fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10

Re:New OpenCL Ray Tracing App...
2010/01/01 10:37:17
(permalink)
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/01 11:54:59
(permalink)
Luv, you're output should be similar to this:
Found 1 platform(s).
platform[0x609e60]: profile: FULL_PROFILE
platform[0x609e60]: version: OpenCL 1.0 CUDA 3.0.1
platform[0x609e60]: name: NVIDIA CUDA
platform[0x609e60]: vendor: NVIDIA Corporation
platform[0x609e60]: extensions: cl_khr_byte_addressable_store cl_khr_gl_sharing cl_nv_compiler_options cl_nv_device_attribute_query
platform[0x609e60]: Found 2 device(s).
device[0x609f10]: NAME: GeForce GTX 260
device[0x609f10]: VENDOR: NVIDIA Corporation
device[0x609f10]: PROFILE: FULL_PROFILE
device[0x609f10]: VERSION: OpenCL 1.0 CUDA
device[0x609f10]: EXTENSIONS: cl_khr_byte_addressable_store cl_khr_gl_sharing cl_nv_compiler_options cl_nv_device_attribute_query cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_fp64
device[0x609f10]: DRIVER_VERSION: 195.17
device[0x609f10]: Type: GPU
device[0x609f10]: EXECUTION_CAPABILITIES: Kernel
device[0x609f10]: GLOBAL_MEM_CACHE_TYPE: None (0)
device[0x609f10]: CL_DEVICE_LOCAL_MEM_TYPE: Local (1)
device[0x609f10]: SINGLE_FP_CONFIG: 0x3e
device[0x609f10]: QUEUE_PROPERTIES: 0x3
device[0x609f10]: VENDOR_ID: 4318
device[0x609f10]: MAX_COMPUTE_UNITS: 24
device[0x609f10]: MAX_WORK_ITEM_DIMENSIONS: 3
device[0x609f10]: MAX_WORK_GROUP_SIZE: 512
device[0x609f10]: PREFERRED_VECTOR_WIDTH_CHAR: 1
device[0x609f10]: PREFERRED_VECTOR_WIDTH_SHORT: 1
device[0x609f10]: PREFERRED_VECTOR_WIDTH_INT: 1
device[0x609f10]: PREFERRED_VECTOR_WIDTH_LONG: 1
device[0x609f10]: PREFERRED_VECTOR_WIDTH_FLOAT: 1
device[0x609f10]: PREFERRED_VECTOR_WIDTH_DOUBLE: 0
device[0x609f10]: MAX_CLOCK_FREQUENCY: 1350
device[0x609f10]: ADDRESS_BITS: 32
device[0x609f10]: MAX_MEM_ALLOC_SIZE: 234799104
device[0x609f10]: IMAGE_SUPPORT: 1
device[0x609f10]: MAX_READ_IMAGE_ARGS: 128
device[0x609f10]: MAX_WRITE_IMAGE_ARGS: 8
device[0x609f10]: IMAGE2D_MAX_WIDTH: 8192
device[0x609f10]: IMAGE2D_MAX_HEIGHT: 8192
device[0x609f10]: IMAGE3D_MAX_WIDTH: 2048
device[0x609f10]: IMAGE3D_MAX_HEIGHT: 2048
device[0x609f10]: IMAGE3D_MAX_DEPTH: 2048
device[0x609f10]: MAX_SAMPLERS: 16
device[0x609f10]: MAX_PARAMETER_SIZE: 4352
device[0x609f10]: MEM_BASE_ADDR_ALIGN: 256
device[0x609f10]: MIN_DATA_TYPE_ALIGN_SIZE: 16
device[0x609f10]: GLOBAL_MEM_CACHELINE_SIZE: 0
device[0x609f10]: GLOBAL_MEM_CACHE_SIZE: 0
device[0x609f10]: GLOBAL_MEM_SIZE: 939196416
device[0x609f10]: MAX_CONSTANT_BUFFER_SIZE: 65536
device[0x609f10]: MAX_CONSTANT_ARGS: 9
device[0x609f10]: LOCAL_MEM_SIZE: 16384
device[0x609f10]: ERROR_CORRECTION_SUPPORT: 0
device[0x609f10]: PROFILING_TIMER_RESOLUTION: 1000
device[0x609f10]: ENDIAN_LITTLE: 1
device[0x609f10]: AVAILABLE: 1
device[0x609f10]: COMPILER_AVAILABLE: 1
device[0x609f70]: NAME: GeForce GTX 260
device[0x609f70]: VENDOR: NVIDIA Corporation
device[0x609f70]: PROFILE: FULL_PROFILE
device[0x609f70]: VERSION: OpenCL 1.0 CUDA
device[0x609f70]: EXTENSIONS: cl_khr_byte_addressable_store cl_khr_gl_sharing cl_nv_compiler_options cl_nv_device_attribute_query cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_fp64
device[0x609f70]: DRIVER_VERSION: 195.17
device[0x609f70]: Type: GPU
device[0x609f70]: EXECUTION_CAPABILITIES: Kernel
device[0x609f70]: GLOBAL_MEM_CACHE_TYPE: None (0)
device[0x609f70]: CL_DEVICE_LOCAL_MEM_TYPE: Local (1)
device[0x609f70]: SINGLE_FP_CONFIG: 0x3e
device[0x609f70]: QUEUE_PROPERTIES: 0x3
device[0x609f70]: VENDOR_ID: 4318
device[0x609f70]: MAX_COMPUTE_UNITS: 24
device[0x609f70]: MAX_WORK_ITEM_DIMENSIONS: 3
device[0x609f70]: MAX_WORK_GROUP_SIZE: 512
device[0x609f70]: PREFERRED_VECTOR_WIDTH_CHAR: 1
device[0x609f70]: PREFERRED_VECTOR_WIDTH_SHORT: 1
device[0x609f70]: PREFERRED_VECTOR_WIDTH_INT: 1
device[0x609f70]: PREFERRED_VECTOR_WIDTH_LONG: 1
device[0x609f70]: PREFERRED_VECTOR_WIDTH_FLOAT: 1
device[0x609f70]: PREFERRED_VECTOR_WIDTH_DOUBLE: 0
device[0x609f70]: MAX_CLOCK_FREQUENCY: 1404
device[0x609f70]: ADDRESS_BITS: 32
device[0x609f70]: MAX_MEM_ALLOC_SIZE: 234831872
device[0x609f70]: IMAGE_SUPPORT: 1
device[0x609f70]: MAX_READ_IMAGE_ARGS: 128
device[0x609f70]: MAX_WRITE_IMAGE_ARGS: 8
device[0x609f70]: IMAGE2D_MAX_WIDTH: 8192
device[0x609f70]: IMAGE2D_MAX_HEIGHT: 8192
device[0x609f70]: IMAGE3D_MAX_WIDTH: 2048
device[0x609f70]: IMAGE3D_MAX_HEIGHT: 2048
device[0x609f70]: IMAGE3D_MAX_DEPTH: 2048
device[0x609f70]: MAX_SAMPLERS: 16
device[0x609f70]: MAX_PARAMETER_SIZE: 4352
device[0x609f70]: MEM_BASE_ADDR_ALIGN: 256
device[0x609f70]: MIN_DATA_TYPE_ALIGN_SIZE: 16
device[0x609f70]: GLOBAL_MEM_CACHELINE_SIZE: 0
device[0x609f70]: GLOBAL_MEM_CACHE_SIZE: 0
device[0x609f70]: GLOBAL_MEM_SIZE: 939327488
device[0x609f70]: MAX_CONSTANT_BUFFER_SIZE: 65536
device[0x609f70]: MAX_CONSTANT_ARGS: 9
device[0x609f70]: LOCAL_MEM_SIZE: 16384
device[0x609f70]: ERROR_CORRECTION_SUPPORT: 0
device[0x609f70]: PROFILING_TIMER_RESOLUTION: 1000
device[0x609f70]: ENDIAN_LITTLE: 1
device[0x609f70]: AVAILABLE: 1
device[0x609f70]: COMPILER_AVAILABLE: 1
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
TheCrazyCanuck
FTW Member
- Total Posts : 1126
- Reward points : 0
- Joined: 2006/04/16 12:54:44
- Location: Texas Yee-Haw!
- Status: offline
- Ribbons : 4
Re:New OpenCL Ray Tracing App...
2010/01/01 12:07:25
(permalink)
Talonman
Thanks...
It is a shame that OpenCL code will have to be optimized for each GPU vendor.
I think that is the reason for the performance difference that we are seeing in this OpenCL app.
One OpenCL code is not best for all GPU brands.
It appears it will always favor one or the other.
I guess it's the curse of GPU programming...
It will be easy to not use the GPU to it's max potential, if you have lots of GPU to PC memory transfers going on.
Actually the layer below the OpenCL layer is where the optimizations should take place. If you had to optimize OpenCL code for each vendor then that defeats the purpose of using it. That's why they use this layered approach, so that the low level grunt work can be tuned while the top layers which are exposed to the programmer are consistent for all vendors. Moving data back and forth between the GPU and processor memory shouldn't be an issue for PCIe to handle. It's just a matter of being intelligent with how you move the data back and forth. Algorithms that pipeline well should hide most/all of the PCIe overhead.
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/01 12:50:49
(permalink)
TheCrazyCanuck
Talonman
Thanks...
It is a shame that OpenCL code will have to be optimized for each GPU vendor.
I think that is the reason for the performance difference that we are seeing in this OpenCL app.
One OpenCL code is not best for all GPU brands.
It appears it will always favor one or the other.
I guess it's the curse of GPU programming...
It will be easy to not use the GPU to it's max potential, if you have lots of GPU to PC memory transfers going on.
Actually the layer below the OpenCL layer is where the optimizations should take place. If you had to optimize OpenCL code for each vendor then that defeats the purpose of using it. That's why they use this layered approach, so that the low level grunt work can be tuned while the top layers which are exposed to the programmer are consistent for all vendors.
Moving data back and forth between the GPU and processor memory shouldn't be an issue for PCIe to handle. It's just a matter of being intelligent with how you move the data back and forth. Algorithms that pipeline well should hide most/all of the PCIe overhead.
Yes on point one. Exactly correct. Which, of course, leaves us at the mercy of Nvidia, ATI, et al. Their implementations of the OpenCL driver and compiler is the critical bit (and harkens right back to that op-ed piece about compilers). Of course devs will need to know the architecture of the hardware they are writing for to device 'smarter' algorithms etc. for respective platforms (just like we have to do for various hardware plaforms...Sparc, x86, PPC, et al). Point two: I'm not sure I agree fully on this. More later, I'm still mucking about ;>) The Nvidia implementation (I don't know if this is because of the compiler, the run time, or the architecture itself) is woefully unoptimized for this app. As you can see, the host is doing the bulk of the computation (look at the numbers Talon has tallied thus far). Why this is I'm not quite sure yet. But it's pretty clear the ATI and Nvidia runtime of this app are vastly different and behave almost at a polar opposite. The ATI runtime is not utilizing the host at all (other than feeding the data) and you see the throughput is dramatically better than the Nvidia runtime (where, of course, the host is being practically overloaded). Where the problem lies is still up in the air. I suppose we could re-write that app from the ground up to find out. I'm just looking for the easy solution :P
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
TheCrazyCanuck
FTW Member
- Total Posts : 1126
- Reward points : 0
- Joined: 2006/04/16 12:54:44
- Location: Texas Yee-Haw!
- Status: offline
- Ribbons : 4
Re:New OpenCL Ray Tracing App...
2010/01/01 13:23:53
(permalink)
Actually what I said is not some opinion that is only from me, all the experts in the high performance computing industry will tell you the same thing when it comes to coprocessors located at the other end of a high latency link. If you can chain the DMA memory transactions and the algorithm can handle additional latency using a pipelining scheme such as ping-pong buffers then you should only be throttled by the compute engine itself. That's a whole bunch of 'ifs' and if your algorithm is hindered by high latency then offloading to the GPU would not be a good idea. Often the mistake I see people make is using highly parallel hardware but using blocking calls which fail to keep the hardware pipe filled. Another one I see is control traffic taking up valuable data cycles across the link. Both of these mistakes are normally due to software developers not knowing enough about the underlining hardware, latencies, etc...
post edited by TheCrazyCanuck - 2010/01/01 13:26:03
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/01 14:10:36
(permalink)
fredbsd
Talon, you want to see something interesting?
Download this: http://davibu.interfree.i...ndelgpu/mandelGPU.html
Then zoom far in. Watch what happens to the image. You'll see it becomes quite pixelated very fast.
These guys explain it here: http://www.luxrender.net/...mp;t=2947&start=20
The zoom on that app gets you into double precision calculations I guess...  "Yup, it is so easy and so fast to zoom in that you end the 32bit floating point resolution very soon. The only solution would be to use 64bit floating points instead of 32bit but there are very few boards supporting them at the moment (I think the new ATI HD5xxx series has the hardware support for double)." "Yup, it is so easy and so fast to zoom in that you end the 32bit floating point resolution very soon. The only solution would be to use 64bit floating points instead of 32bit but there are very few boards supporting them at the moment (I think the new ATI HD5xxx series has the hardware support for double)."
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M) 
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/01 14:15:54
(permalink)
fredbsd
The Nvidia implementation (I don't know if this is because of the compiler, the run time, or the architecture itself) is woefully unoptimized for this app. As you can see, the host is doing the bulk of the computation (look at the numbers Talon has tallied thus far). Why this is I'm not quite sure yet. But it's pretty clear the ATI and Nvidia runtime of this app are vastly different and behave almost at a polar opposite. The ATI runtime is not utilizing the host at all (other than feeding the data) and you see the throughput is dramatically better than the Nvidia runtime (where, of course, the host is being practically overloaded).
Where the problem lies is still up in the air. I suppose we could re-write that app from the ground up to find out. I'm just looking for the easy solution :P
I was begging for a pure CUDA port, to see if it was just an OpenCL thing, and not a GPU performance thing, but no takers... http://forums.nvidia.com/...e&showtopic=154318 'CudaRun'
From the details on egva forum it looks like AMD Stream processors are better while running OpenCL.
But strangely I have a strong belief that the overall score (how fast a given problem is solved) is a combination of factors
1) time taken to divide the problem in between the processors
2) time taken to solve the problem (taking into account any vector routines and hardware function implementations)
3) time taken to combine the results to form the final result
Possibly the current OpenCL bench mark favors AMD with large number of stream processors. But for a true bench mark the benchmark should actually take into consideration other factors as well. possibly nVidia is slow on OpenCL to give importance to their upcoming C++ CUDA
Your investigation is disturbing :rolleyes: . I am really interested to find this out before making an significant investment buying GPU for numerical calculations.
I feel inclined to tell you that we now have a member trying to figure out why Nvidia has such poor performance, in the second OpenCL example listed above... We may still be able to track down the reason for the high CPU utilization? http://forums.evga.com...863&mpage=3#101441 It would be nice to have some more experienced programmers also look into this, and join in the fight for Team Nvidia! We could use the help, and our OpenCL image could use a boost. I think final Nvidia performance is still pending on this app too... I wonder if this ray-tracing app was written in pure CUDA, if our Sample/sec would go way up? I still am not sure how much better an app written in CUDA, would perform, over the same app written in OpenCL. This might be a good app to use an an experiment on performance, CUDA -vs- OpenCL? I'd love to see the results.  Can anybody tell me how hard it would be to get these 99 lines of C++ open source code into a working CUDA program, get it decently optimized, and all ready to run for us on Windows? Can anybody tell me how hard it would be to get these 99 lines of C++ open source code into a working CUDA program, get it decently optimized, and all ready to run for us on Windows? (And add multi-GPU support if possible?) http://www.kevinbeason.com/smallpt/ We might then do much better? The sad performance stats with our current OpenCL implementation. DosDuoNo ----------- GTX 260 --- Sample/sec --- 1,093.2K Chumbucket843 ---- GTX 260 --- Sample/sec --- 1,123.2K Talonman ---------- 1/2 a 295 --- Sample/sec --- 1,159.2K NovoRei --------------- 4870 ------ Sample/sec --- 5,616.1K PyrO ------------- 1/2 a 4870X2 -- Sample/sec --- 5,796.2K mattkosem ----------- 4890 ------ Sample/sec --- 6,751.6K fellix bg --------------- 5870 ------ Sample/sec -- 13,719.6K luv2increase --------- 5870 ------ Sample/sec -- 14,883.7K You can see why it just doesn't sit right with me, simply leaving things a grey area.  You probably think I'm a nut, but I actually believe those 99 lines of code, is costing Nvidia money right now.  What a thrill it would be, to see that flip! I am still chomping at the bit to make initial contact with Pat, programmer of the first OpenCL app listed above: http://www.ngohq.com/grap...mark-10.html#post87400 He is still on vacation until the 4th. Performance between GPU's, may yet be closer than we think...  We need a strong comeback. I was hoping a CUDA expert would just jump in, and be our hero. That didn't happen. We need a strong comeback. I was hoping a CUDA expert would just jump in, and be our hero. That didn't happen.
post edited by Talonman - 2010/01/01 14:27:40
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M)
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/01 14:37:30
(permalink)
TheCrazyCanuck
Talonman
Thanks...
It is a shame that OpenCL code will have to be optimized for each GPU vendor.
I think that is the reason for the performance difference that we are seeing in this OpenCL app.
One OpenCL code is not best for all GPU brands.
It appears it will always favor one or the other.
I guess it's the curse of GPU programming...
It will be easy to not use the GPU to it's max potential, if you have lots of GPU to PC memory transfers going on.
Actually the layer below the OpenCL layer is where the optimizations should take place. If you had to optimize OpenCL code for each vendor then that defeats the purpose of using it. That's why they use this layered approach, so that the low level grunt work can be tuned while the top layers which are exposed to the programmer are consistent for all vendors.
Moving data back and forth between the GPU and processor memory shouldn't be an issue for PCIe to handle. It's just a matter of being intelligent with how you move the data back and forth. Algorithms that pipeline well should hide most/all of the PCIe overhead.
I found this post interesting... http://forums.nvidia.com/.dex.php?showtopic=108761 'avidday'
I don't think so. Both NVIDIA and ATI are supplying special beta drivers with OpenCL support, but I don't believe either company have OpenCL support in their current release drivers. Further to that, I don't believe it is possible to build a single application that can run on either flavour of hardware. You can take OpenCL code and compile it with either vendor's SDK and it will probably work, but the back end code and support libraries are completely different and incompatible. Further to that, both flavours of OpenCL are really in beta and the performance and capabilities of both appears to be inferior to either vendors proprietary GPU compute environments (ie. CUDA or Stream).
It gave me the impression that 1 code may work on both GPU's, but 1 GPU vendor will loose real bad in performance. It also confirmed for me that CUDA would be faster than OpenCL.
post edited by Talonman - 2010/01/01 14:41:19
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M)
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/01 14:57:26
(permalink)
TheCrazyCanuck
Actually what I said is not some opinion that is only from me, all the experts in the high performance computing industry will tell you the same thing when it comes to coprocessors located at the other end of a high latency link. If you can chain the DMA memory transactions and the algorithm can handle additional latency using a pipelining scheme such as ping-pong buffers then you should only be throttled by the compute engine itself. That's a whole bunch of 'ifs' and if your algorithm is hindered by high latency then offloading to the GPU would not be a good idea.
Often the mistake I see people make is using highly parallel hardware but using blocking calls which fail to keep the hardware pipe filled. Another one I see is control traffic taking up valuable data cycles across the link. Both of these mistakes are normally due to software developers not knowing enough about the underlining hardware, latencies, etc...
Thanks for the clarification. I was sort of hinting at the many 'ifs' ;>).
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
TheCrazyCanuck
FTW Member
- Total Posts : 1126
- Reward points : 0
- Joined: 2006/04/16 12:54:44
- Location: Texas Yee-Haw!
- Status: offline
- Ribbons : 4
Re:New OpenCL Ray Tracing App...
2010/01/01 17:40:45
(permalink)
Ya I usually don't go into much detail since I have a hard enough time explaining this to customers let alone to gamers :) Odd though, I never thought the kind of stuff I work on would ever show up in the EVGA forums lol
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/01 17:55:02
(permalink)
TheCrazyCanuck
Ya I usually don't go into much detail since I have a hard enough time explaining this to customers let alone to gamers :) Odd though, I never thought the kind of stuff I work on would ever show up in the EVGA forums lol
Hehe..well...technically I'm not a 'real gamer'....;>) Talon is real gung-ho on the possibilities of GPU work and benchmarking. Excitement breeds enthusiasm or however that goes so I sort of just followed along. I have never coded in OpenCL or CUDA so I'm learning as I go so to speak. It's interesting for sure. I am really trying to avoid re-writing that app... but I don't think that's going to work out in my favour. Band-aids aren't working. ;>( My biggest problem: I feel 'dirty' working in Linux or Windows for too long. I start to break out in hives, fever, blisters, all that stuff. So it's going to be a very slow process. :P
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/01 19:00:58
(permalink)
Hrmm...'unsupported platform'...my arse. I can compile and run the CPU program...and oddly enough it performs far better on BSD (only ~80'ish % utilization on 1 core which of course keeps my desktop nice and responsive...unlike....that other not-to-be-named-Unix-wannabe-OS :P). At least I can work on that code now over here. Thank goodness. 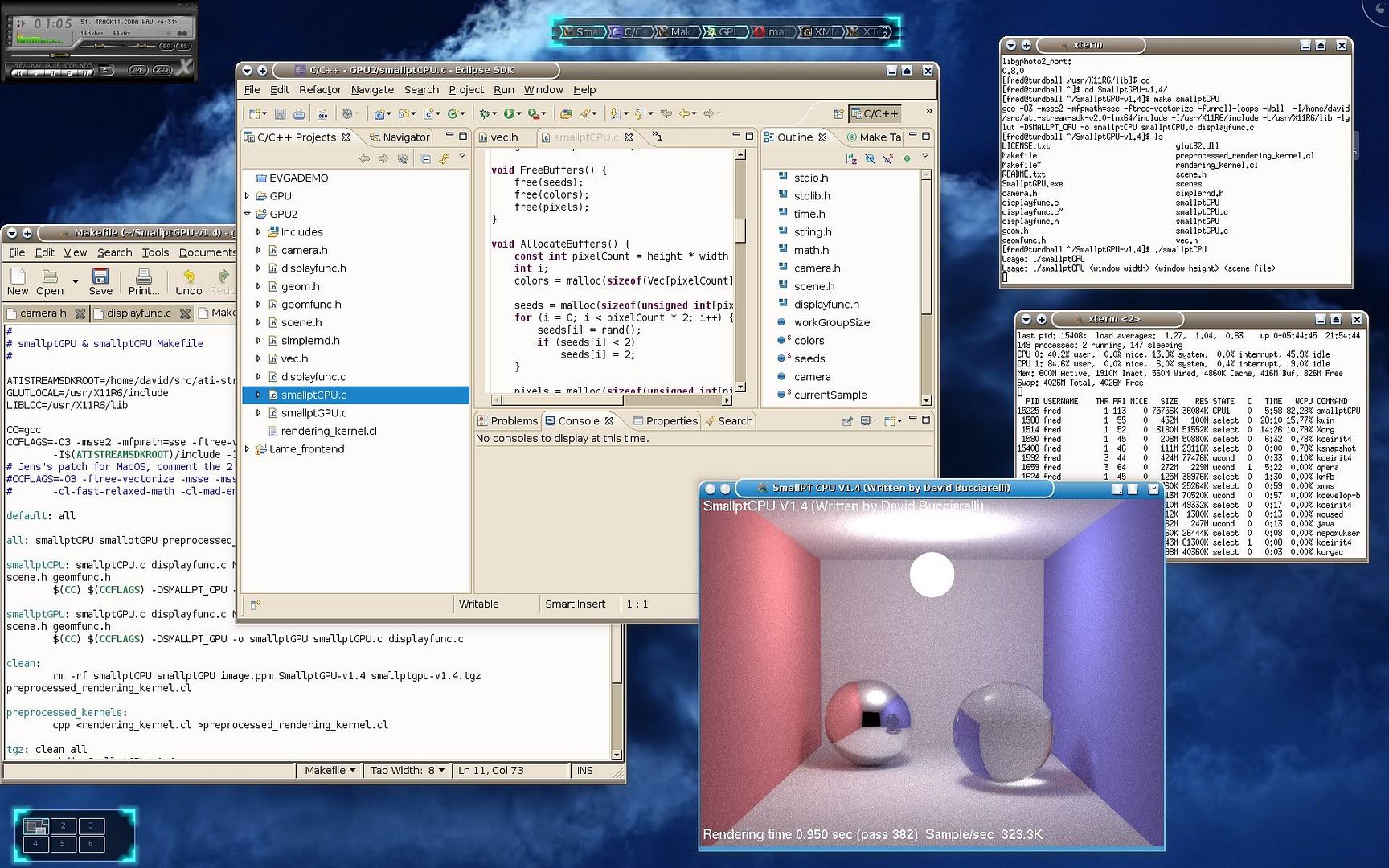
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/01 19:55:51
(permalink)
One more...then I'm done... CC, can you explain this to me? I am not sure I full understand. device[0x609f10]: GLOBAL_MEM_CACHELINE_SIZE: 0 device[0x609f10]: GLOBAL_MEM_CACHE_SIZE: 0 That's what's reported when I run that query app I linked earlier. I'll be honest, I haven't done that much research on it...but seems odd that there's local memory (I'm assuming that's on the video card itself) and 0 reported for global cache (again, I'm assuming the global cache is on the host). That strikes me as a bit odd (hence why I want someone using the ATI driver run it and report back). The kernel parameters are all being passed in __global scope (memory buffers). If I am to read this right, the driver is reporting there is 0 global cache available...which again...strikes me really odd. I tried to create the buffers locally, but of course I get the out of resources failure (hehe...at least I tried :P). Any light you could shed on this would be greatly appreciated. I could be barking up the wrong tree entirely...I honestly don't know. edit: the GLOBAL MEMORY reported is what's on the card (896 MB). I'm confuzzled. Is global memory considered on the card and the host? Wait.... I think I'm answering my own question here...I really should read the spec hehe.
post edited by fredbsd - 2010/01/01 20:05:14
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/01 19:59:09
(permalink)
323.3K Sample/sec running off 1 core of a CPU.
If it used all 4 cores on a quad core CPU, that would get you 1,293.2K Sample/sec
Better than I could do:
Talonman ---------- 1/2 a 295 --- Sample/sec --- 1,159.2K
I think this app just hates Nvidia!
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M)
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/01 20:13:44
(permalink)
Talonman
323.3K Sample/sec running off 1 core of a CPU.
If it used all 4 cores on a quad core CPU, that would get you 1,293.2K Sample/sec
Better than I could do:
Talonman ---------- 1/2 a 295 --- Sample/sec --- 1,159.2K
I think this app just hates Nvidia!
I think Nvidia hates OpenCL :P Hehe, FreeBSD is...outstanding. It's not for the faint of heart or the impatient...but it certainly is quite solid. www.freebsd.org (shameless, unabashed plug). Read what they did with the scheduler. ;>) It would be nice if Nvidia would support OpenCL on this platform. It's doubtful, but then again we had our doubts about 64 bit drivers and we got them. Edit: Here's the details... 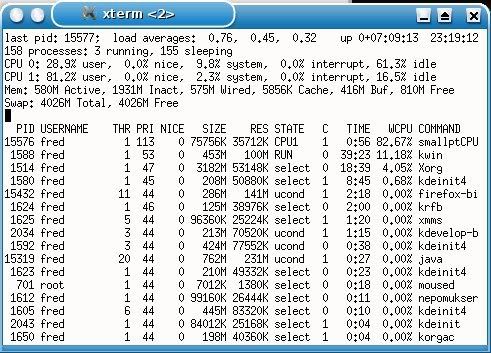
post edited by fredbsd - 2010/01/01 20:22:38
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/01 20:18:26
(permalink)
That is why if we had a CUDA port, and took OpenCL out of the equation, we could then see if our performance numbers would change.
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M)
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/01 20:27:32
(permalink)
Talonman
That is why if we had a CUDA port, and took OpenCL out of the equation, we could then see if our performance numbers would change.
Not necessarily. I think there's more to it than that. I'm, of course, still fishing around. Hopefully CC can shed some light on the topic. BTW, I tossed a screenie of cpu utilization in the last post.
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
chumbucket843
iCX Member
- Total Posts : 469
- Reward points : 0
- Joined: 2009/04/15 19:21:56
- Status: offline
- Ribbons : 0
Re:New OpenCL Ray Tracing App...
2010/01/01 20:42:39
(permalink)
Core i7 D0 EVGA X58 LE EVGA GTX260\\folding 3x2 GB DDR3 *10 real cores folding
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/01 20:48:17
(permalink)
chumbucket843
http://forum.beyond3d.com/showpost.php?p=1374679&postcount=16
i dare you to click on this link...
Hahah...yeah. The author is aware of the 'issues' with the nvidia situation. A few folks have applied some patches, but it hasn't helped yet. Nvidia's OpenCL implementation obviously is choking on this particular app (although it does just fine with a few of his other ports). A mystery that remains to be solved.
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/01 22:28:41
(permalink)
Thanks!! "Hi, I'm David, the author of SmallptGPU. I think I can clarify few points:
- About the poor performances on Nvidia, I have developed SmallptGPU on an ATI HD4870. Both ATI and NVIDIA OpenCL drivers are in a early stage of the development and have their fair amount of problems/bugs/etc. I have avoided problematic paths on ATI because is my card while I have never tested SmallptGPU on NVIDIA. I assume I'm doing something that the NVIDIA OpenCL driver doesn't like at all. The high CPU usage is a good hint of this problem.
- The sources are available on the web site, so if anyone has a fix for NVIDA cards, I will be happy to apply it.
- SmallptGPU uses the first GPU device available (there is a command line option to run on CPU device). About all the load should be on GPU, CPU is nearly unused. It is not able to use multiple devices at the same time so any SLI/CrossFire configuration will be used only at 50% of its capabilities.
- 5870 is horrible fast ... I' trying to not buy one"
Also for trivia. I was looking here...
http://code.google.com/p/tokaspt/
Found a CUDA app that I am going to see how I do speed wise on, and noticed it had adjustment sliders that change performance.

Max Paths changes performance, I wonder if it is just such fine tuning that also needs to happen with this SmallptGPU?
Glad the programmer is on it!
post edited by Talonman - 2010/01/01 22:32:38
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M)
|
Via Sin Dios
SSC Member
- Total Posts : 851
- Reward points : 0
- Joined: 2007/05/07 14:18:24
- Status: offline
- Ribbons : 1

Re:New OpenCL Ray Tracing App...
2010/01/01 22:45:03
(permalink)
Microcool Banchetto 101 Samsung UN46C8000 LED Intel 2500K @ 4.6 on Water 30c Corsair Vengeance 2x4 gig @ 1600 GTX 1080 TBD EVGA P67 FTW EVGA 1k Watt Seagate barracuda HDD RAID 0 x2 Win 10 http://www.heatware.com/u/63225
|
fredbsd
FTW Member
- Total Posts : 1622
- Reward points : 0
- Joined: 2007/10/16 13:23:08
- Location: Back woods of Maine
- Status: offline
- Ribbons : 10
Re:New OpenCL Ray Tracing App...
2010/01/02 08:21:57
(permalink)
Via Sin Dios
mystery solved then
Yep. The app was completely re-written. edit: wait...no....that app Talon just linked was written prior to the OpenCL one.
post edited by fredbsd - 2010/01/02 10:52:54
"BSD is what you get when a bunch of Unix hackers sit down to try to port a Unix system to the PC. Linux is what you get when a bunch of PC hackers sit down and try to write a Unix system for the PC."
|
TheCrazyCanuck
FTW Member
- Total Posts : 1126
- Reward points : 0
- Joined: 2006/04/16 12:54:44
- Location: Texas Yee-Haw!
- Status: offline
- Ribbons : 4
Re:New OpenCL Ray Tracing App...
2010/01/02 11:26:09
(permalink)
fredbsd
One more...then I'm done...
CC, can you explain this to me? I am not sure I full understand.
device[0x609f10]: GLOBAL_MEM_CACHELINE_SIZE: 0
device[0x609f10]: GLOBAL_MEM_CACHE_SIZE: 0
That's what's reported when I run that query app I linked earlier. I'll be honest, I haven't done that much research on it...but seems odd that there's local memory (I'm assuming that's on the video card itself) and 0 reported for global cache (again, I'm assuming the global cache is on the host). That strikes me as a bit odd (hence why I want someone using the ATI driver run it and report back).
The kernel parameters are all being passed in __global scope (memory buffers). If I am to read this right, the driver is reporting there is 0 global cache available...which again...strikes me really odd. I tried to create the buffers locally, but of course I get the out of resources failure (hehe...at least I tried :P).
Any light you could shed on this would be greatly appreciated. I could be barking up the wrong tree entirely...I honestly don't know.
edit: the GLOBAL MEMORY reported is what's on the card (896 MB). I'm confuzzled. Is global memory considered on the card and the host?
Wait....
I think I'm answering my own question here...I really should read the spec hehe.
Not sure, I actually don't work with GPUs and OpenCL/CUDA, I develop specialized hardware accelerators and software stacks to go with them. I would expect the global memory to be what is reported on the card (not sure what they would do in SLI/Crossfire enable). The cache properties would be tricky to report since each cluster has it's own memory controller and L1/L2 cache depending on the architecture. Knowing what the cache size and line size would be handy so that you can determine how large of a structure should be used and attempt to keep data aligned on cache line boundaries to improve performance (limit cache thrashing). As long as the data set is localized to a single cluster at a time then the trashing should be minimal if coded properly and the algorithm allows it. So with OpenCL, CUDA, or any hardware accelerator that contains local memory you would want to perform a DMA transfer from the host processor memory space to the GPU global memory, perform the number crunching, and then DMA the data back to the processor memory space. Although I don't like the name 'global memory' to describe what is really a BAR on the PCIe bus it kinda makes sense for GPUs since each cluster has it's own cache and local scratch pad memories (newer cards... 2xx and 5xxx series from Nvidia and ATI I believe). ......Now if only I had free time to fart around with OpenCL :(
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/09 19:15:58
(permalink)
Just for trivia boys, we are up to V2.0 Alpha, with Multi-GPU Support. If you get any interesting results, I will be glad to rub Davids nose on this thread. http://forum.beyond3d.com...php?t=55913&page=5
post edited by Talonman - 2010/01/09 19:17:13
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M)
|
Spongebob28
iCX Member
- Total Posts : 317
- Reward points : 0
- Joined: 2009/01/08 12:14:47
- Location: AL
- Status: offline
- Ribbons : 1
Re:New OpenCL Ray Tracing App...
2010/01/10 14:41:44
(permalink)
I want to join in on the games.
V2.0 Alpha
Geforce 8800 GT Perf. index 1.00 Workload done 34.2%
Geforce GTX 295 Perf. index 2.28 Workload done 21.8%
Geforce GTX 295 Perf. index 2.28 Workload done 44.0%
Rending time 0.625 sec pass 447 Sample/sec 1820.8K
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/10 16:08:20
(permalink)
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M)
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/12 02:23:21
(permalink)
FYI - Dave has now installed manual tuning, on your multi-GPU workload distribution: 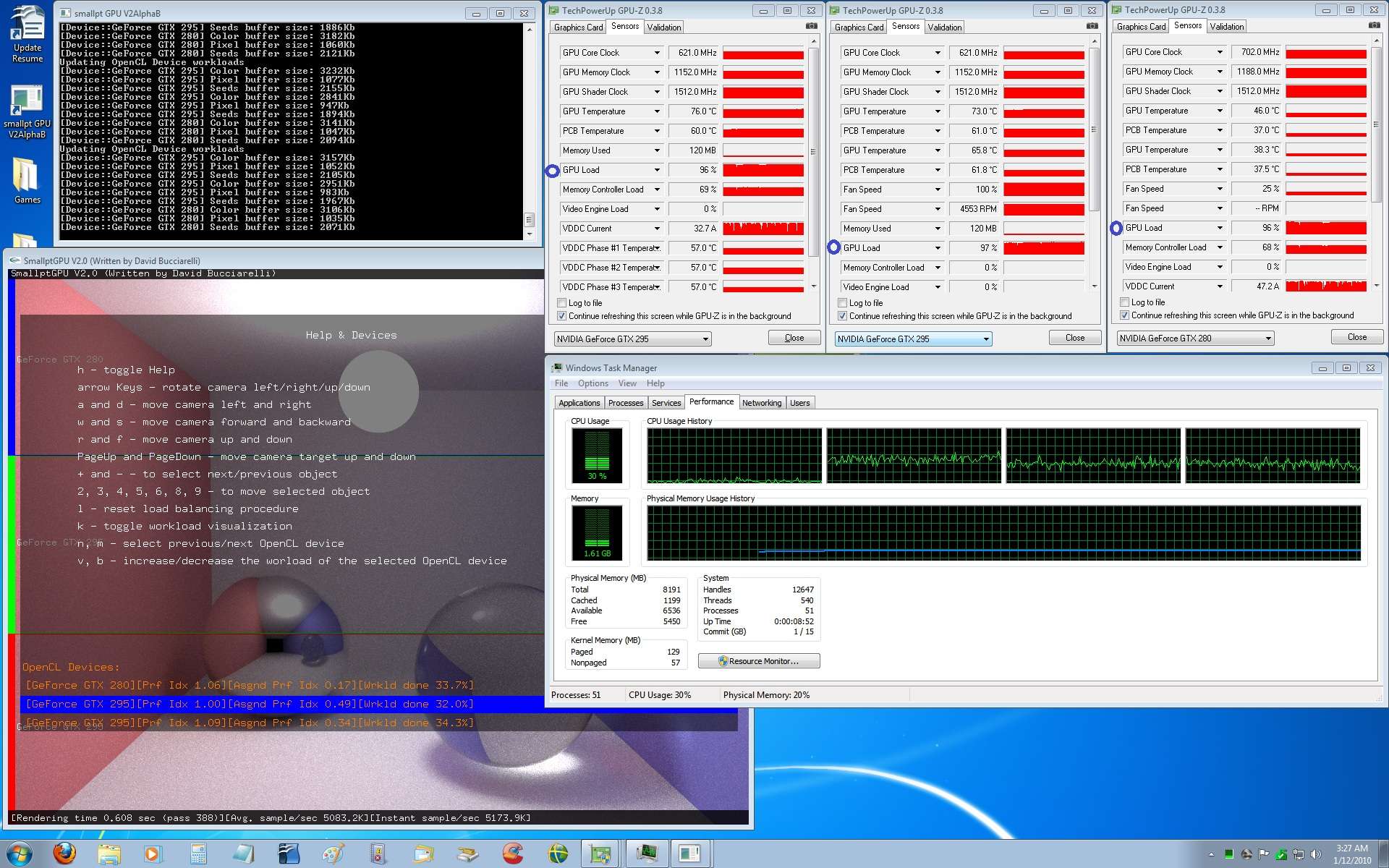 The app is working well...
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M)
|
Spongebob28
iCX Member
- Total Posts : 317
- Reward points : 0
- Joined: 2009/01/08 12:14:47
- Location: AL
- Status: offline
- Ribbons : 1
Re:New OpenCL Ray Tracing App...
2010/01/12 14:09:45
(permalink)
It sure does!!! With Manuel tuning, I jumped to Sample/sec 2397.7K 8800 GT Wrkld 26.6% 295 GTX Wrkld 38.9% 295 GTX Wrkld 34.5%
post edited by Spongebob28 - 2010/01/12 14:12:37
|
Talonman
FTW Member
- Total Posts : 1391
- Reward points : 0
- Joined: 2008/04/01 09:26:53
- Location: Ohio
- Status: offline
- Ribbons : 31
Re:New OpenCL Ray Tracing App...
2010/01/12 14:12:33
(permalink)
Good deal, and thanks for the report.
Asus ROG Maximus IX Hero Z270 / i7-7700K / Windows 10 Pro / EVGA GTX 1080 TI FTW3 Elite GPU / 32GB G.SKILL TridentZ RGB Series DDR4 3200MHz / EVGA Super Nova 850 G3 80 Plus Gold Modular PSU / Case: Phanteks Eclipse P400 in Red / (1) Samsung 960 EVO M.2 Internal SSD 500GB for OS (2) Samsung 850 EVO 1TB in RAID-0 for games / (1) Western Digital Black 7200 RPM 3TB Hard Drive for system backups - EVGA CLC 280 CPU Cooler. (EVGA affiliate code SKLZ84OQ2M)
|
Spongebob28
iCX Member
- Total Posts : 317
- Reward points : 0
- Joined: 2009/01/08 12:14:47
- Location: AL
- Status: offline
- Ribbons : 1
Re:New OpenCL Ray Tracing App...
2010/01/12 14:20:08
(permalink)
Did you know you can increase performance my increasing the Suggested work group size in the batch file. When running the app, I noticed it would suggest 192 for my 8800 GT and 384 for my 295 GTXs. I'm limited to 192 due to the 8800GT. If I trying anything higher, it crashes the app.
P.S. The above scores are unaltered. I just ran the app as is.
|